Alexander Libman
Author thanks Vladimir Gilbourd for the long TProactor discussions on Coogee Beach, Sydney and help in writing of this article.
Comparison of I/O Multiplexing & Scalable Socket Servers design patterns and implementations.
The purpose of this article is to investigate different non-blocking I/O multiplexing mechanisms and to propose a single multi-platform design pattern/solution. We also compare the performance Java, C# and C++ implementations of this solution.
We will not consider blocking approach at all here, because of its well-known performance and scalability problems.
Two I/O Multiplexing Approaches
In his article “I/O Multiplexing & Scalable Socket Servers“, Ian Barile [1] compares Thread Pooling and I/O Multiplexing development alternatives for scalable socket servers. He concludes that I/O multiplexing provides much better scalability and performance and proposes cross-platform implementation for MS-Windows and Sun Solaris. In this article we will try to extend the discussion about performance and cross-platform compatibility issues and will try to propose a more generic approach to solve them.
In general terms, I/O multiplexing mechanisms rely on Event Demultiplexor (main event dispatcher) [2, 3]. Its function is to wait/monitor I/O events and to dispatch them to the appropriate event (read/write) handlers. The developer registers his interest in specific events and provides event handlers (callbacks) for them. Demultiplexor delivers requested events to event handlers.
The nature of the actual event (“system is ready for I/O operation” vs. “I/O operation completed”) is what distinguishes two different design patterns, described in [2, 3]:
- The synchronous (sync) Event Demultiplexor (Reactor pattern[2]) waits for event “file descriptor / socket is ready for read/write”. It is the task of the handler itself to perform the actual read/write operation.
- The asynchronous (async) Event Demultiplexor (Proactor pattern [2]): handler (or Demultiplexor on behalf of the handler) initiates the async read/write operation. This operation is performed by OS asynch API (e.g. Overlapped IO on Windows). Operation parameters include addresses of user-defined data buffers, where OS puts (or gets from) data to read (or write). OS provides a notification mechanism for a completion of I/O operation. The Demultiplexor waits for completion (e.g. using IOCompletionPort on Windows) and dispatches event to the appropriate event handler. Implementation of this classic asynchronous pattern is based on an asynchronous OS-level API and we will call it the “System-level” or “True” Async (because application fully relies on OS to execute actual I/O).
Synchronous and asynchronous event demultiplexing example scenarios.
Let us describe the difference in further details (for simplicity we will consider the “read” operation only, as the “write” implementation is similar):
Reactor:
- event handler declares interest in I/O events (readiness for read on socket);
- dispatcher waits for events (e.g. on select ());
- event comes in and wakes-up the dispatcher; dispatcher calls appropriate handler;
- event handler performs actual operation (reads data), handles data, declares new interest in I/O events and returns control to the dispatcher.
Proactor (“True” Async)
- handler initiates async read operation (OS should support async I/O). In this case handler does not care about “I/O readiness” events, but it is interested in “completion events”. It is the dispatcher task to wait until operation is completed and notify handler when completion has happened;
- dispatcher waits for completion events,
- while dispatcher waits, OS executes read operation in parallel kernel thread, puts data into user defined buffer and notifies dispatcher (completion event), dispatcher calls appropriate handler;
- event handler handles “ready-for-use” data from user defined buffer, starts new asynchronous operation and returns control to the dispatcher.
Current status/practice.
Open-source C++ development framework ACE (www.cs.wustl.edu/~schmidt/ACE.html) [2, 3], developed by Douglas Schmidt et al, offers a wide range of platform independent, low-level concurrency support classes (threading, mutexes, etc). On the top level it provides two separate groups of classes: implementations of the ACE Reactor and of the ACE Proactor. Although both of them are based on platform-independent primitives, they have different interfaces.
The ACE Proactor gives much better performance and robustness on MS-Windows (it has async API) while the ACE Reactor is a preferable solution in UNIX (currently UNIX does not have robust async facilities for sockets). As we can see, at present, existing solutions do not provide the required flexibility and developers have to maintain two separate code-bases: ACE Proactor for Windows and ACE Reactor for Unix-based systems.
Problem.
As it was mentioned above, the True Async Proactor pattern requires OS-level support. Unfortunately, not all operating systems provide full robust async OS-level support - e.g. Unix-based systems do not.
Due to a different nature of “event handler – OS” interaction it is difficult to create common, unified external interfaces for both Reactor and Proactor patterns. This makes it hardly possible to create fully portable development framework and encapsulate interfaces’ and OS’s differences.
Proposed solution.
Now, let us convert the first scenario to the second one by moving read/write operations from event handlers inside the Demultiplexor – and we will get an “Emulated Async”. Let us explain this conversion by example (again, just for “read” operation):
- event handler declares interest in I/O events (readiness for read) and provides the demultiplexor with extra information (address of buffer “where to put data” and number bytes to read);
- dispatcher waits for events (for example - on select ());
- event comes in and wakes up dispatcher; dispatcher performs non-blocking read operation (it has all necessary information to perform this operation) and on completion calls appropriate handler;
- event handler handles “ready-for-use” data from user-defined buffer, declares new interest (plus information about the “where to put data” buffer and number bytes to read) in I/O events and returns control to the dispatcher.
As we can see, by adding some extra functionality to Demultiplexor we were able to convert the Reactor pattern to a Proactor pattern. In terms of the amount of work performed, this approach is exactly the same as the Reactive pattern. We just shifted responsibilities between different actors – this cannot cause performance degradation.
If we have OS, which does not provide async API, this approach allows us to hide the reactive nature of available socket APIs and to expose a fully proactive async interface. This allows us to create a fully portable platform-independent solution with a common external interface.
TProactor.
The proposed solution (TProactor) was developed and implemented at Terabit P/L (www.terabit.com.au). It has two alternative implementations – in C++ and in Java. The C++ version was built using ACE cross-platform low-level primitives and has a common unified async “proactive” interface on all platforms.
In terms of design, the main components of TProactor are Engine and WaitStrategy interfaces. Engine is a component, which manages async operations lifecycle. WaitStrategy manages concurrency strategies. WaitStrategy depends on Engine and they work always in pairs. Interfaces between Engine and WaitStrategy are strongly defined.
Engines and waiting strategies are implemented as pluggable class-drivers (for the full list of all implemented Engines and corresponding WaitStrategies see Appendix 1). TProactor is a highly configurable solution, it internally implements three engines (POSIX AIO, SUN AIO and Emulated AIO) and hides six different waiting strategies – based on an asynchronous kernel API (for POSIX- not efficient right now due to internal POSIX AIO API problems) and synchronous Unix select(), poll(), /dev/poll (Solaris), RealTime (RT) signals (Linux), k-queue (FreeBSD) APIs. TProactor conforms to the standard ACE Proactor implementation interface. This makes possible to develop a single cross-platform solution (POSIX/MS-WINDOWS) with a common (ACE Proactor) interface.
With a set of different mutually interchangeable Engines and WaitStrategies (“Lego-style” modular approach) and according to specific requirements (number of connections, scalability, etc) and targeted OS, the developer can choose the appropriate internal mechanism (engine and waiting strategy) at run time by setting appropriate configuration parameters. If OS supports async API – use the “True Async” approach, otherwise the user has a choice of “Emulated Async” solutions built on different “sync” waiting strategies (all of them are hidden behind emulated async façade!!).
For the Sun Solaris HTTP server, for example, /dev/poll-based Engine will be the most suitable choice (able to serve huge number of connections), but for generic UNIX solution with limited number of connections, but high requirements to throughput – select()-based Engine will be the best approach. This fine-tuning cannot be done with a standard ACE Reactor/Proactor (for inherent algorithmic problems of different ‘waiting strategies” see Appendix 2).
In terms of performance, it is clear from our examples that emulating “from reactive to proactive” does not impose any overhead – it can be faster, but not slower. As the matter of fact, according to our extensive test results, the TProactor gives on average up to 10-35 % better (as it was pointed before, even in the worst scenario) performance than the reactive model (in standard ACE Reactor implementation) on various UNIX/Linux platforms. On Windows it gives the same performance as standard ACE Proactor.
Performance comparison (JAVA versus C++ versus C#).
The next step was to implement TProactor in Java. As we know, Java 1.4 provides only the sync based approach, logically similar to C select().
The following charts (transfer rate bit/sec versus number of connections) represent comparison results between simple echo-server built on standard ACE Reactor(RedHat Linux 9.0), TProactor (C++ and Java (IBM 1.4JVM) - MSWin and RedHat Linux9.0) and C# echo-server (MSWin). Performance, achieved by native AIO APIs is represented by "Async" marked curves; by emulated AIO (TProactor) – “AsyncE” curves; by TP_Reactor – “Synch” curves. All implementations were bombed by the same client applcation - continuous stream of arbitrary fixed size messages via N connections.
Java TProactor is based on Java non-blocking facilities (java.nio packages) logically similar to C++ TProactor with waiting strategy based on select().
The full set of tests was performed on the same hardware. Tests on different machines proved that relative results are consistent.
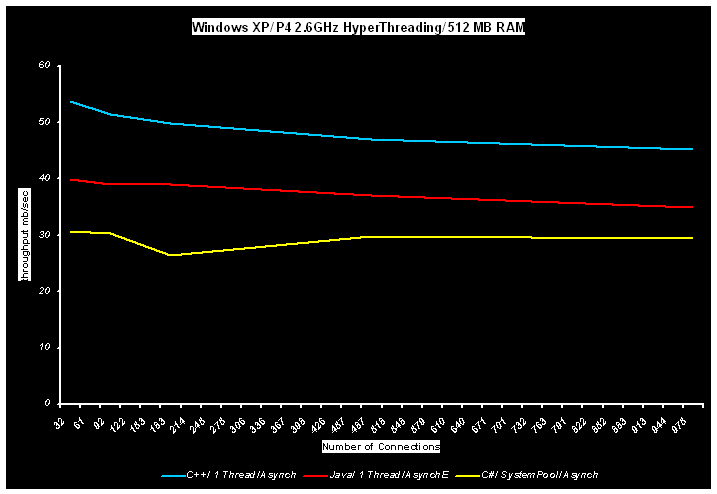
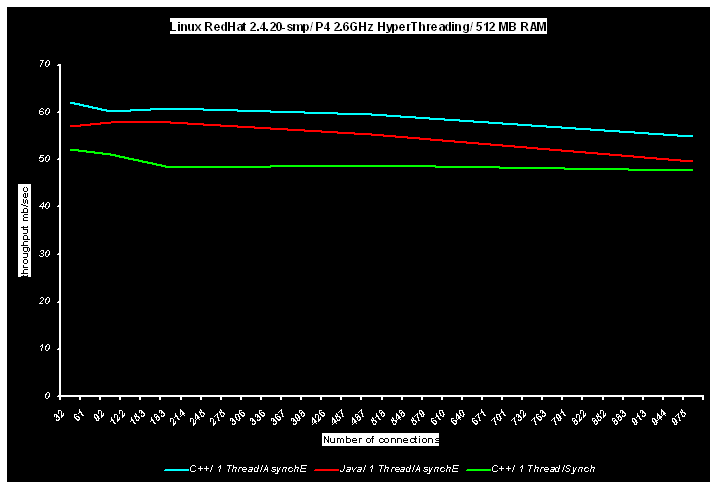 .
.
User code example.
The following is the skeleton of a simple TProactor based Java echo-server. In a nutshell, the developer only has to implement interfaces OpRead (with buffer, where TProactor puts “read” results) and OpWrite (with buffer, from where TProactor takes “what to write”) and implement protocol-specific logic via providing callbacks onReadCompleted() and onWriteCompleted() in ProtocolHandler interface implementation. Those callbacks will be asynchronously called by TProactor on completion of read/write operations and executed in thread pool space provided by TProactor (developer don’t need to write his own pool).
class EchoServerProtocol implements ProtocolHandler
{
IOHandler handler = null;
EchoServerProtocol( Multiplexor m, SelectableChannel channel ) throws Exception
{
this.handler = new IOHandler( m, this, channel );
}
public void start() throws Exception
{
// called after construction
System.out.println( Thread.currentThread().getName() + ": EchoServer protocol started" );
handler.read( buffer);
}
public void onReadCompleted( OpRead opRead ) throws Exception
{
if ( opRead.getError() != null )
{
// handle error, do clean-up if needed
System.out.println( "EchoServer::readCompleted: " + opRead.getError().toString());
handler.close();
return;
}
if ( opRead.getBytesCompleted () <= 0)
{
System.out.println( "EchoServer::readCompleted: Peer closed " + opRead.getBytesCompleted() ;
handler.close();
return;
}
ByteBuffer buffer = opRead.getBuffer();
handler.write(buffer);
}
public void onWriteCompleted(OpWrite opWrite) throws Exception
{
// logically similar to onReadCompleted
….
}
}
IOHandler is one of TProactor base classes. ProtocolHandler and Multiplexor, among other things, internally executes chosen by developer “waiting strategy”.
Conclusion
TProactor provides common single highly adaptive and configurable solution for multi-platform high-performance communications development.
It is clear for the charts, that C++ is still the preferable approach for high performance communication solutions, but Linux Java is coming quite close. However, the overall "Linux - Window" cross-platform portability rating for Java was weakened by poor Windows results.
Taking into account the latest activities to develop robust AIO on Linux [7] we can conclude, that Linux Kernel API (io_xxxx set of system calls) should be more scalable in comparison with POSIX standard, but still not portable. In this case, TProactor with new Engine/Wait Strategy pair, based on native LINUX AIO can be easily implemented to overcome portability issues and to cover Linux native AIO with standard ACE Proactor interface.
Appendix 1.
Engines and waiting strategies implemented in TProactor
|
Engine Type |
Wait Strategies |
OS |
|
POSIX_AIO (True Async) |
Aio_suspend |
POSIX complained UNIX (not robust) |
|
aio_read()/aio_write() |
Waiting for RT signal |
POSIX (not robust) |
|
|
Callback function |
SGI IRIX, LINUX (not robust) |
|
SUN_AIO (True Async) aioread()/aiowtite() |
Aiowait |
SUN (not robust) |
|
Emulated Async |
Select() |
generic POSIX |
|
Non-blocking read()/write |
poll() |
Mostly all POSIX implementations |
|
|
/dev/poll |
SUN |
|
|
Linux RT signals |
Linux |
|
|
Kqueue |
FreeBSD |
Appendix 2.
All sync waiting strategies can be divided into two groups:
- edge-triggered (e.g. Linux RT signals) – signal readiness only when socket became ready (changes state);
- level-triggered (e.g. select, pol, /dev/poll) – readiness at any time.
Let us describe some common logical problems for those groups:
edge-triggered group: after executing I/O operation, the demultiplexing loop can loose the state of socket readiness. Example: the “read” handler did not read whole chunk of data, so the socket remains still ready for read. But demultiplexor loop will not receive next notification.
level-triggered group: when demultiplexor loop detects readiness, it starts the write/read user defined handler. But before the start, it should remove socket descriptior from the set of monitored descriptors. Otherwise, the same event can be dispatched twice.
Obviously, solving these problems adds extra complexities to development. All these problems were resolved internally within TProactor and the developer should not worry about those details, while in the synch approach one needs to apply extra effort to resolve them.
REFERENCES:
1. Ian Barile “I/O Multiplexing & Scalable Socket Servers“, 2004 February, DDJ
2. Douglas C. Schmidt, Stephen D. Huston “C++ Network Programming.” 2002, Addison-Wesley ISBN 0-201-60464-7
3. Dough C. Schmidt, Michael Stal, Hans Rohnert, Frank Buschmann “Pattern-Oriented Software Architecture: Patterns for Concurrent and Networked Objects, Volume 2” Wiley & Sons, NY 2000
4. W. Richard Stevens “UNIX Network Programming” vol. 1 and 2, 1999, Prentice Hill, ISBN 0-13-490012-X”
5. INFO: Socket Overlapped I/O Versus Blocking/Non-blocking Mode. Q181611. Microsoft Knowledge Base Articles.
6. Further reading on event handling - http://www.cs.wustl.edu/~schmidt/ACE-papers.html
7. Linux AIO development - http://lse.sourceforge.net/io/aio.html; http://archive.linuxsymposium.org/ols2003/Proceedings/All-Reprints/Reprint-Pulavarty-OLS2003.pdf